これからDeep Learningの開発環境を導入していきますが、その前にDeep Learningについて簡単に説明します。Deep Learningは、日本語では深層学習と呼ばれている機械学習の研究分野の一つで、データを高次に抽象化するための多階層なモデルを学習する技術の総称です。
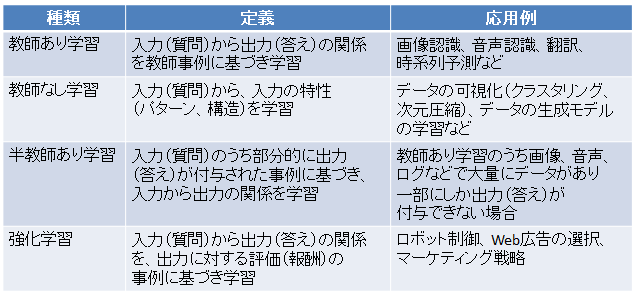
機械学習の枠組みには、大きく分けて教師あり学習、教師なし学習、半教師あり学習および強化学習があります。
(引用元強くなるロボティック・ゲームプレイヤーの作り方 実践で学ぶ教科学習)
これらの機械学習の方法は、入力(質問)として数値ベクトルを前提にしています。そのため、機械学習の枠組みを、画像認識などに応用するためには、それぞれの応用に合わせてデータをベクトルに変換する必要があります。このデータからベクトルへの変換のことを特徴抽出と呼びます。この特徴抽出は、それぞれの応用に関する専門的な知識が必要なため、画像認識などの応用研究者が活躍する分野でした。例えば、画像分類では、Fisher vectorやORBなど多くの特徴抽出方法が提案されてきました。
近年、Deep Learningの研究が進むにつれて、機械学習の活躍の場は、この特徴抽出まで広がってきました。Deep Learningでは教師あり学習、教師なし学習、半教師あり学習及び強化学習の枠組みを拡張し、それぞれの目的に応じて、画像などのデータを抽象化されたベクトルに変換する階層的なモデルを学習しています。教師あり学習では、Deep Convolutional Neural NetworkやDeep Auto-encoder、教師なし学習ではDeep Belief NetworkやDeep Boltzmann Machine、強化学習では、Deep Q-learningなどが代表的な方法として知られています。この特徴量を自動的に抽出するDeep Learningに対比して、これまでの特徴抽出方法は、ハンドクラフト特徴量と呼ばれています。
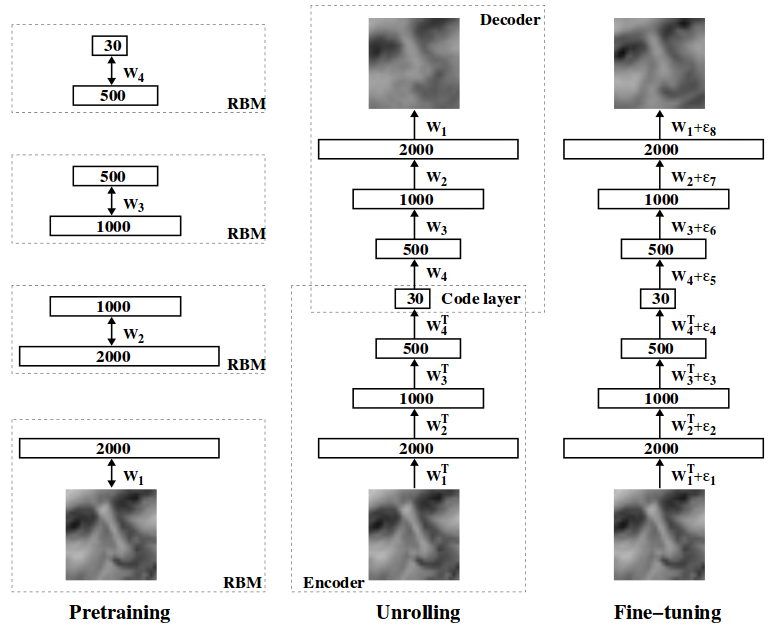
Deep Learningが脚光を集め始めるきっかけとなったのは、2006年にトロント大学のGeoffrey E. Hinton先生などによりScienceで発表された論文「Reducing the Dimensionality of Data with Neural Networks」です。本論文では、多階層のニューラルネットワークのパラメータを、教師なし学習のDeep Belief Networkを用いて初期化した後に、教師あり学習のBack propagationにより再学習するというものでした。このパラメータの初期化をプレトレーニング(Pre-training)、再学習をファインチューニング(Fine-tuning)と呼びます。
【Deep Belief NetworkをDeep Auto-encoderのプレトレーニングに用いる場合の例】
【Deep Belief Networkを画像分類のプレトレーニングに用いる場合の例】
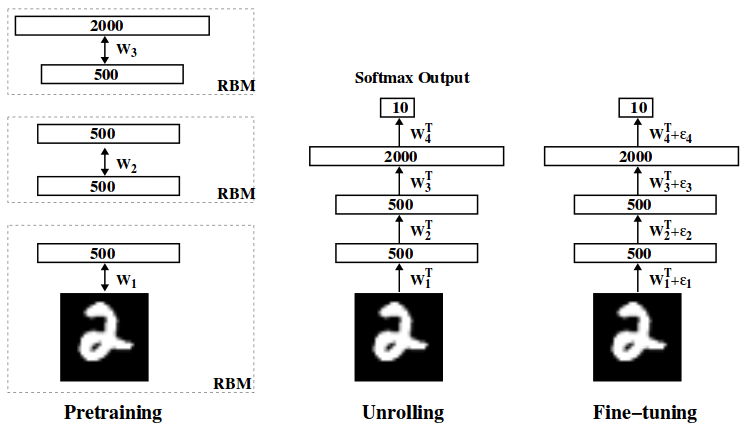
このプレトレーニングは、多階層のニューラルネットワークの教師あり学習において、低階層のパラメータが更新されないgradient vanishing問題を回避する方法として話題を集めました。具体的には、教師あり学習のBack propagationでは、ニューラルネットワークの出力と教師情報の出力の誤差を最小化するように、勾配法により各層のパラメータを更新します。しかしながら、低階層のパラメータの勾配は、出力までにアクティベーション関数のシグモイド関数が何度もかかっているため、ほぼ0になってしまいます。そのため、勾配法では低階層のパラメータはほとんど更新されません。つまり、勾配が消滅してしまうため、gradient vanishing問題と呼ばれています。
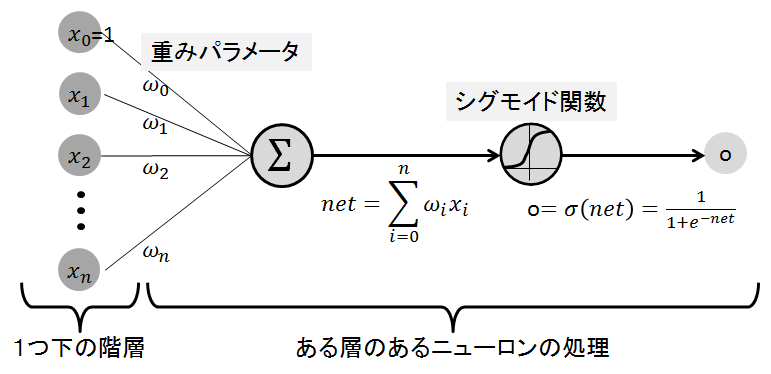
【ニューラルネットワークの各階層の各ニューロンの処理】
【gradient vanishing問題のイメージ】
シグモイド関数が1重(single)、2重(double)、および3重(triple)とかかる度に勾配が小さくなるのがわかります。
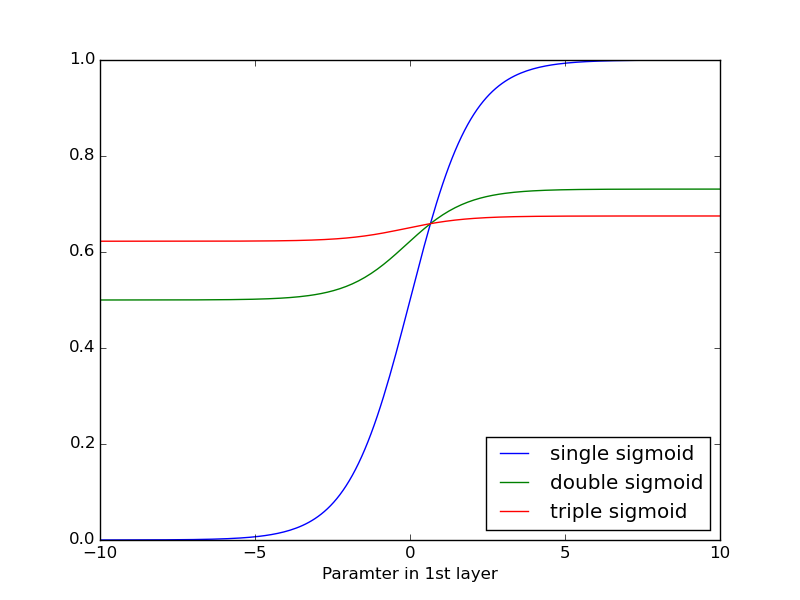
そして、本論文にて、Hintonらは、Back propagationにより学習できない低階層のパラメータを、教師なし学習のプレトレーニングにより学習することにより、このgradient vanishing問題を回避しています。
しかし、近年、ImageNetの大規模画像分類、Large Faces in the Wildの顔認識およびUCF101の行動認識にて、Deep Learningがこれまで主流だったハンドメード特徴量を凌駕し人間と同程度の精度を出して話題になっているのは、教師あり学習のDeep Convolutional Neural Network(Deep CNN)であり、残念ながら教師なし学習と教師あり学習の組み合わせによるプレトレーニングとファインチューニングは使われていません。具体的には、ImageNetは、毎年開催されるコンペティションで、画像を1,000クラスに分類する分類タスクと、画像上の物体の場所を特定し200クラスに分類する検出タスクとの2つのタスクがあります。2012年のImageNetの分類タスクにおいて、トロント大学のHintonのグループによるDeep CNNが、それまで全盛であったハンドメード特徴量に10%以上の大差をつけて優勝しました。そして、2013年以降は、上位のほとんどがDeep CNN系の方法となる状況となっています。
【2012年の分類タスクの上位の結果】

【Imagenetの画像の例と、分類タスクの誤差率の推移】
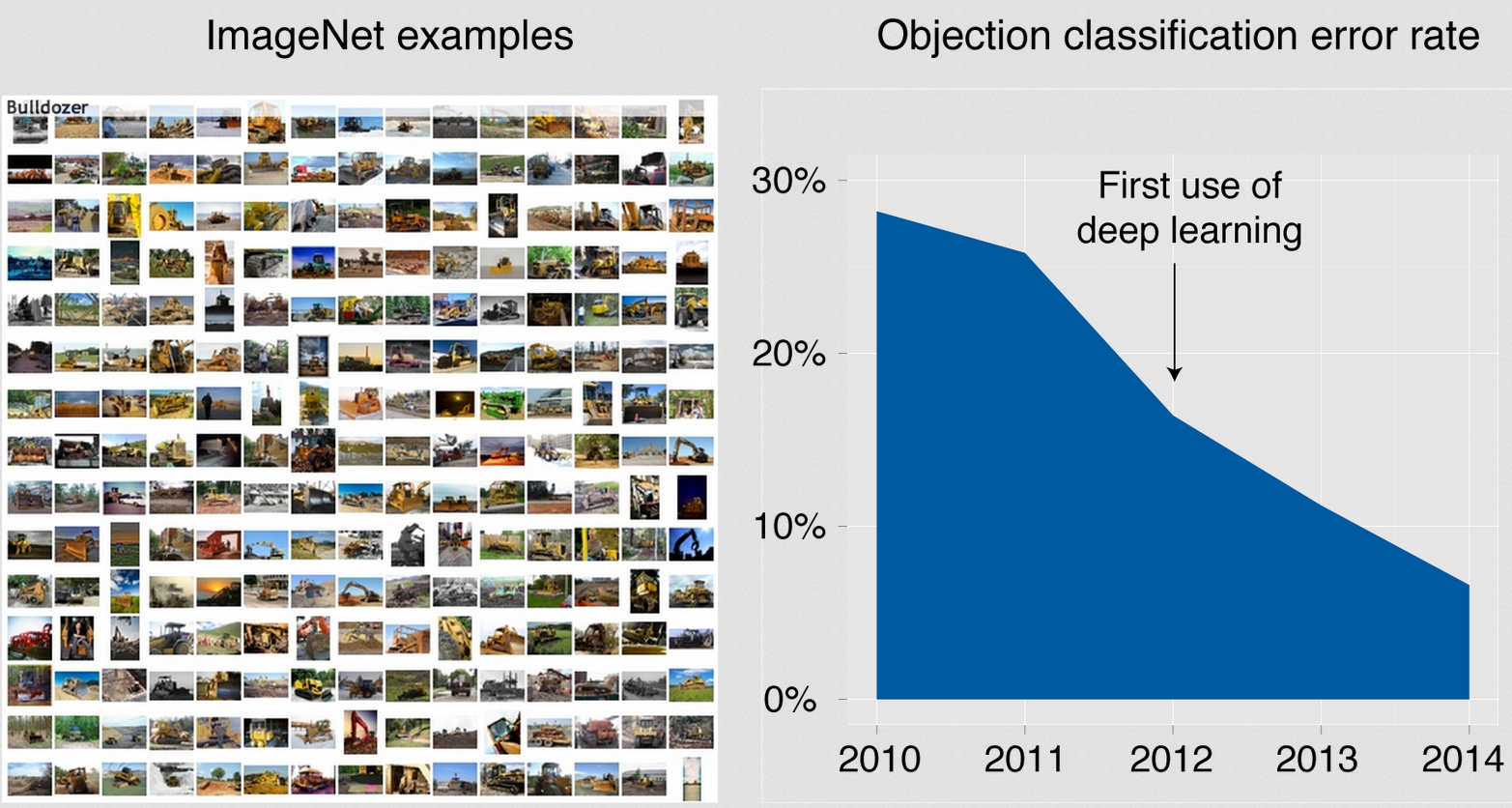
(引用元:http://www.enlitic.com/tech.html)
このHintonのグループのDeep CNNは、筆頭著者の名前をとってAlexNetと呼ばれています。AlexNetでは、Yann LeCunによって1998年に提案されたLeNet5を多階層に拡張し、さらに、gradient vanishingの問題を解決するために、アクティベーション関数としてシグモイド関数の代わりにRectified Linear Unit(ReLU)を用いてるのが特徴です。
【LeNet5の構造】

(引用元:Gradient-Based Learning Applied to Document Recognition, Y. LeCun et al., 1998)
【AlexNetの構造】
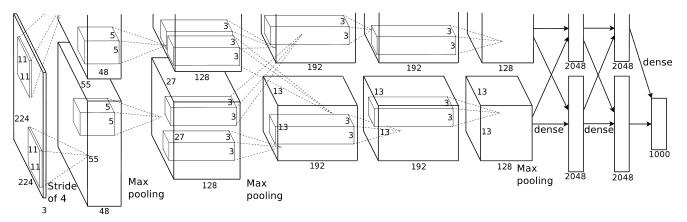
(引用元:ImageNet Classification with Deep Convolutional Neural Networks, A. Krizhevsky et al., NIPS2012)
次回からは、このAlexNetを代表するDeep CNNを実装するための環境の導入について説明していきます。また、AlexNetの詳細についても、説明していきます。